


 Key Findings
Key Findings
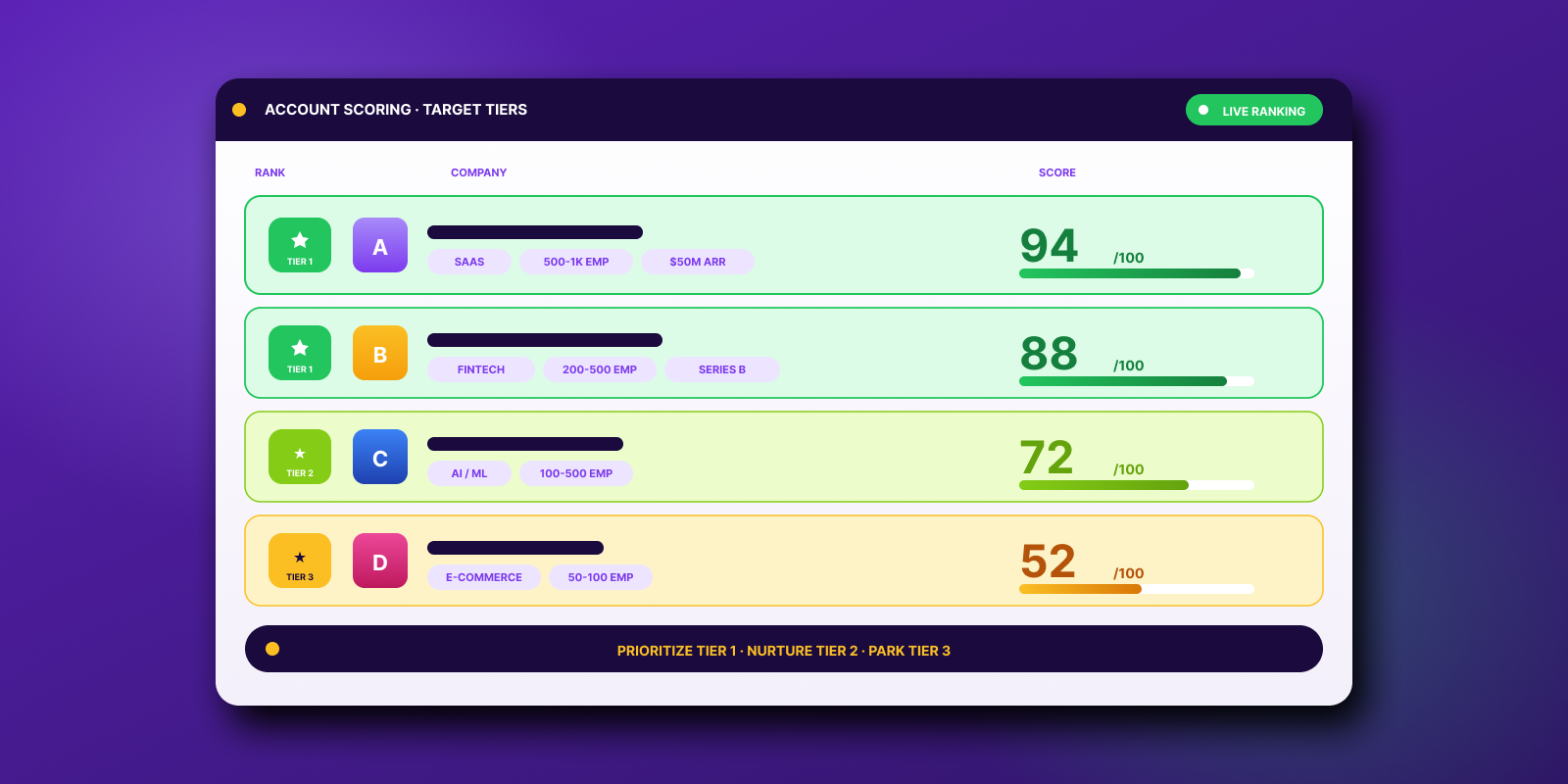
Domains and authentication, warm-up and scale, list hygiene, monitoring. Break any one and the others start failing in ways that look random.
Use brand-adjacent sending domains. SPF, DKIM, and DMARC configured before any campaign goes live. Protect your real company email from outbound traffic.
Industry consensus on volume per mailbox. Scale by adding lanes, not by squeezing single inboxes harder. Keep warm activity running even after campaigns go live.
Email data decays fast. Verify within 48 hours of sending. Hard bounces, complaints, and unsubscribes never re-enter rotation.
Bounces means data. Complaints means targeting. Single-provider drops means authentication or volume. Copy is the last thing to rewrite, not the first.
Your open rates fell off a cliff. Again.
You rewrote the subject lines, softened the CTA, shortened the first line. Maybe you blamed the copy. None of that fixes the underlying problem if your sending setup is weak.
Cold email deliverability usually breaks long before the prospect reads a word. Mailbox providers judge your infrastructure first, your sending behaviour second, and your copy after that. If your domain setup is sloppy, your mailboxes are rushed, and your list is stale, you are not running outbound. You are lighting domains on fire.
The better question is not how to fix cold email deliverability with a few tricks. The better question is how to build a sending system that stays healthy while campaigns run every day. That system has four parts, and most teams break at least two of them.
If you need a copy layer once the infrastructure is sorted, the cold email response rate 2026 benchmarks guide covers what good looks like and how to lift yours. If part of your volume runs through AI-generated workflows, keeping AI agent emails out of spam is worth reading because the same reputation rules apply to automation.
Why your cold emails are really going to spam
Most senders misdiagnose deliverability.
They think spam placement means the message is weak. Sometimes it is. More often, the primary issue is that mailbox providers do not trust the sender.
A lot of outbound advice is shallow. Change the subject line. Remove one link. Personalise the opener. Fine. Those things matter later. If your domain has no real reputation, your authentication is half-configured, and you are pushing mail through inboxes that were never warmed properly, the campaign is dead before the first prospect ignores it.
The real problem is fragile infrastructure
Cold email is an operating system, not a template.
You need a protected domain strategy, properly authenticated inboxes, strict volume control, clean data, and active monitoring. Miss one part and the rest starts failing in ways that look random. Open rates drop. Replies dry up. Bounce rates creep up. Then someone blames market saturation when the underlying issue is self-inflicted.
Your copy cannot rescue a sender reputation problem.
Most founders and SDR managers fall into this trap. They keep adjusting campaign copy because that feels easier than touching DNS, mailbox health, or list hygiene. That cycle explains why the same problem comes back every quarter.
Spam is a system failure
If you want inbox placement that holds up, stop treating deliverability like a one-time setup task.
Build the system so problems get blocked before they start. That means isolating your main domain, authenticating every sending domain, warming inboxes with discipline, verifying lists before launch, and watching reputation signals every day. Do that and deliverability becomes manageable. Skip it and every campaign becomes a gamble.
Build the foundation: domains and authentication
A founder launches outbound from the company's main domain, books a few replies, then notices customer emails landing in spam two weeks later. That mistake is avoidable. Your cold email setup should contain risk, not spread it across the entire business.
Never send cold outreach from your primary domain.
Use separate sending domains built for outbound only. Pick close variants of your brand so the domain still looks legitimate to prospects, but keep your real company domain out of campaign traffic. If one sending domain gets flagged, your sales motions slow down. Your support, hiring, finance, and founder email stay untouched.
Separate domains by function
Treat outbound infrastructure like a portfolio, not a single sender identity.
Buy a small set of adjacent domains. Create outbound-only inboxes on each one. Keep campaign traffic, reply handling, and any testing inside that environment. Do not mix outbound with customer conversations or day-to-day company email. That separation is what gives you room to scale, pause, replace, and recover without taking down the rest of your email operation.
This is the part outbound teams rush. They buy domains, connect a sending tool, and assume the software solves trust. It does not. Sending platforms can automate volume and rotation. They cannot fix a bad domain plan or a broken DNS setup.
SPF, DKIM, and DMARC need to be finished before launch
Authentication is how mailbox providers verify that your mail is allowed to come from your domain.
- SPF lists the servers allowed to send on behalf of your domain.
- DKIM signs each message so receiving servers can verify it was not altered.
- DMARC tells receiving servers how to handle mail that fails those checks and gives you reporting on alignment and abuse problems.
If any one of these is missing or misconfigured, you create doubt at the exact point where providers decide whether to trust you. That doubt hurts placement before your copy, offer, or targeting gets judged.
A practical setup looks like this:
Build for replacement, not perfection
Good outbound infrastructure assumes something will burn out.
A sending domain can lose placement. An inbox can drift. A mailbox provider can tighten filtering with no warning. If your whole program depends on one domain and a handful of inboxes, every issue becomes urgent. If you spread outbound across dedicated domains and properly configured inboxes, you can pause one lane, replace it, and keep the system running.
That is the goal here. You are not patching deliverability after it breaks. You are building an outbound base that survives normal wear without taking the company down with it.
The setup rules we use
We keep this simple and strict.
- Use brand-adjacent domains only for outbound. Never recycle the main company domain for campaign traffic.
- Create dedicated inboxes for sending. Outbound accounts exist for outbound only.
- Finish DNS setup before any campaign goes live. SPF, DKIM, and DMARC are configured and checked first.
- Keep roles separate. No cold outreach from founder, support, recruiting, or customer success inboxes.
- Plan for domain rotation. Have backup sending capacity ready before you need it.
Teams that follow this model avoid the usual pattern of short-lived results followed by a deliverability collapse. Teams that ignore it keep blaming copy, tooling, or market conditions for problems they created in DNS and domain strategy.
Warm up like an operator, scale like an engineer
You buy a fresh domain, connect a few inboxes, push a campaign on day three, and watch reply rates die by lunch. That failure starts long before the copy gets judged. It starts with sending behaviour that looks synthetic from the first week.
Warm-up is reputation building. Scaling is load management. Treat them as one system.
Mailbox providers do not grade your intent. They grade patterns. A new inbox that suddenly behaves like a sales robot gets filtered like one. The fix is simple. Build a believable history first, then increase volume in small steps that the inbox can absorb without changing its behaviour overnight.
Warm-up should create normal mailbox behaviour
A good warm-up period gives each inbox a baseline. It sends messages at uneven times, generates real thread activity, and avoids the sharp spikes that make a fresh account look automated. If you use a warm-up tool, keep the goal clear. You are not trying to inflate activity. You are trying to make the mailbox look stable, boring, and human.
Microsoft says sender reputation is shaped by user engagement and complaint patterns, not just raw send volume, in its guidance on email deliverability and sender reputation for Outlook. Google makes the same point in its Email sender guidelines, where bulk senders are told to keep spam rates low and maintain consistent sending behaviour.
That is why warm-up fails for outbound teams that rush into campaigns. They focus on volume targets instead of behaviour patterns.
Use a controlled ramp, not a dramatic launch
Keep the ramp plain.
- Start each inbox with low activity.
- Increase volume in small increments every few days.
- Keep warm-up traffic running while campaign volume comes online.
- Spread sends across multiple inboxes instead of forcing one account to carry the whole program.
- If you need more capacity, add more inboxes. Do not ask a single mailbox to become your entire outbound engine.
Industry consensus from top deliverability articles: cap each sending address at ≤100 emails per day to mimic human behaviour and protect placement.
The operating rule we use:
- Warm each inbox before it touches prospecting traffic.
- Increase volume gradually, not in weekly jumps.
- Keep send timing irregular enough to avoid machine-like patterns.
- Hold back capacity on every domain so you can absorb issues without shutting down outreach.
- Scale by adding lanes, not by squeezing harder on the same lane.
That last point matters more than teams admit. Good outbound infrastructure is built for replacement. If one inbox slips, you should be able to pause it, swap in another, and keep campaigns running without a full reset.
Know when an inbox is ready to carry real volume
A warm inbox is not ready because a tool says it is. It is ready when it handles normal traffic without obvious stress signals.
Check the basics. Replies should come in without delays that feel abnormal. Placement should stay steady across major providers. Bounce behaviour should stay clean. The inbox should tolerate a small increase in campaign traffic without a visible drop in engagement or a sudden rise in filtering.
Then scale carefully.
Do not stop warm-up and slam the account with production volume. Blend the two. Add live sends in controlled batches and watch what changes after each increase. If performance drops, pull volume back fast and isolate the inbox before the problem spreads across the domain.
If your targeting depends on shaky contact records, scaling gets harder because every inbox takes unnecessary hits. Clean prospect inputs matter as much as warm-up discipline, especially if you are enriching lists before launch with signal-based outbound workflows.
Most teams blame copy when deliverability breaks. We see the opposite. Nine times out of ten the problem is in the DNS, the warm-up, or the list. Fix those three, the copy you already have starts working again.

What actually breaks inboxes during scale
Outbound teams usually damage sender reputation the same way. They warm for a short stretch, see a few replies, then jump straight to campaign volume. Or they keep adding sends to the same inbox because it worked last week. Both are lazy operating decisions.
The safer model is boring by design. Multiple domains. Multiple dedicated inboxes. Controlled ramps. Ongoing warm activity. Spare capacity. Clear pause rules.
You do not fix cold email deliverability by waiting for placement to collapse and then hunting for a tool. You build a sending system that stays stable as volume grows.
Treat data as part of your sending infrastructure
You launch a clean campaign on a healthy inbox, then the reply rate dies and bounces stack up by day two. That usually is not a domain problem. It is a data problem.
Bad data poisons outbound faster than weak copy. One stale list can turn a stable sending setup into a reputation cleanup project. If you want deliverability that holds up at scale, treat list quality as infrastructure, not prep work.
Your list starts going bad the moment you export it
People change jobs. Companies shut down inboxes. Teams migrate domains. Shared spreadsheets keep circulating long after the records inside them are wrong.
ZeroBounce explains that email data decays quickly and recommends validating addresses before campaigns, not months in advance, in their analysis of email list decay and verification timing. Their guidance aligns with the rule good outbound teams already follow. Hard bounces should be removed fast, and old records should never be trusted without a fresh check.
Build a data gate before any inbox sees volume
Run outbound data through three filters.
Use better inputs. Start with sources that give you useful company and contact context, not just an email field. Job changes, firmographic filters, and recent signals matter because they help you avoid sending valid email to the wrong person. If your team is enriching lead records before launch, a structured signal-based outbound process cleans up most downstream deliverability issues.
Verify right before the send. Verification done too early creates false confidence. Mailgun recommends validating email addresses at the point of capture and again before sending because addresses can become invalid over time, in their email verification best practices. The standard sequence is simple: export, segment, verify, send. In that order.
Suppress permanently. Hard bounces, unsubscribes, spam complainers, and known bad-fit contacts should never re-enter rotation. HubSpot is clear on list hygiene in its email list management guidance: remove invalid and disengaged contacts to protect sender reputation and keep complaint risk down.
This process is boring. Good. Boring systems protect domains.
Valid emails still hurt you if the targeting is sloppy
A verified address is not the same thing as a good prospect.
Outbound teams often obsess over verification and ignore fit. Then they blast a large list of technically valid contacts who do not care, do not reply, and do not recognise the sender. That pattern tanks engagement, and low engagement gives mailbox providers another reason to filter you harder.
The fix is tighter segmentation before copy ever gets written. Filter by role, company profile, current pain, and recent trigger. Build smaller batches around specific offers. Relevance protects deliverability because it produces the positive signals your infrastructure needs to stay trusted.
Small targeted lists keep inboxes healthier than large lists full of weak-fit contacts.
What we cut from every list
Before a campaign goes live, remove these records:
- Role accounts like info@, support@, admin@, and hello@
- Catch-all or risky addresses your verifier cannot confirm with confidence
- Old records that have not been re-verified close to send time
- Previous hard bounces
- Unsubscribes and spam complainers
- Low-fit contacts added only to inflate volume
Outbound operators run into trouble when they keep weak records because they want a bigger top of funnel. Bigger volume does not help if the inputs are dirty. It just spreads reputation damage across more inboxes.
Monitor, troubleshoot, and handle bounces in the right order
A campaign can look fine at 9 a.m. and be damaged by lunch.
That is why deliverability monitoring belongs inside your operating system, not as a cleanup task after results drop. If you wait until reply rates crash, you are already late. The job here is simple: catch trust loss early, isolate the cause fast, and stop bad sends before they spread reputation damage across the rest of your setup.
Watch the metrics that predict trouble
Open rate is a weak control metric. It is noisy, privacy-distorted, and easy to misread. Track the signals that tell you whether mailbox providers still accept your mail and whether your targeting still deserves inbox placement.
The core dashboard should include:
A specific Gmail-versus-Outlook example: if Gmail placement drops while Outlook holds steady, the likely culprit is DKIM alignment or a recent Google bulk-sender threshold change. Check your DMARC reports for that domain before touching anything else.
For pacing, follow-up control, and reply handling, your sequence logic matters too. Poor timing can create the same reputation problems as bad data. A clear signal-based outbound playbook keeps the system controlled as volume grows.
Troubleshoot in the right order
Do not start with copy.
Start with failure type, because each symptom points to a different break in the system. If you troubleshoot from the template first, you waste time and keep sending through a setup that may already be compromised.
Use this order:
- Bounce rate rises first. Assume bad records, stale verification, or a broken source.
- Spam complaints rise. Assume weak targeting, a bad offer match, or copy that sounds deceptive or irrelevant.
- One provider drops harder than the others. Check authentication alignment, recent volume jumps, and domain health for that provider.
- Replies disappear while delivery looks normal. Check segmentation, offer fit, and CTA friction.
That sequence keeps you from making the common outbound mistake of rewriting emails when the problem sits in list sourcing, infrastructure, or send behaviour. Diagnose sender health first, then data quality, then targeting, then copy.
Bounce handling needs rules, not judgment calls
Manual bounce cleanup is how bad addresses slip back into future sends. Build automatic suppression and keep it strict.
A healthy outbound system should treat these as default rules:
- Hard bounce once, suppress forever
- Unsubscribe once, suppress forever
- Complaint or hostile reply, exclude immediately
- Soft bounce patterns, review by provider and mailbox
- Old segments, re-verify before reuse
These rules protect more than inbox placement. They protect scale. A system that relies on someone remembering which CSV to clean will fail as volume increases.
Good monitoring protects revenue, not just reputation
Deliverability work gets framed as defensive. That is the wrong view.
The same discipline that protects inbox placement also protects pipeline quality. Clean suppression, provider-level monitoring, and fast troubleshooting keep strong domains active and bad segments contained. That lets you scale the parts of outbound that work instead of burning the full setup because one campaign went sideways.
This is the difference between reactive sending and resilient infrastructure. Reactive teams keep mailing until a domain is cooked. Operators with a real system see the warning signs, cut the failing segment, preserve the healthy mailboxes, and keep the machine running.
A pre-launch operator checklist
Before any new domain or sequence goes live, run through this list. If anything is unchecked, do not send.
- Sending domain is brand-adjacent, not the primary
- SPF, DKIM, DMARC configured and tested with a DNS checker
- DMARC reporting set up and feeding into a mailbox you actually read
- Sending mailboxes warmed for at least 14 to 21 days before campaign traffic
- Volume capped at ≤100 sends per mailbox per day
- List verified within 48 hours of send
- Role accounts, catch-alls, and previous bounces suppressed
- Segmentation locked: one persona, one trigger, one offer per cohort
- Daily monitoring dashboard configured for bounce, complaint, provider-level placement, positive reply
- Backup mailbox capacity ready in case one slips
This list is boring. Operators who run it ship campaigns that do not collapse. Operators who skip it usually call us 90 days later when the domain is cooked.
Putting it all together: the outbound system
Cold email deliverability is not one trick.
It is a four-part system: protected domains with proper authentication, disciplined warm-up and controlled scaling, strict list hygiene, and daily monitoring that catches trouble before a domain gets burned.
That is the difference between reactive outbound and durable outbound. Reactive teams wait for open rates to collapse, then scramble. Serious teams build infrastructure that makes collapse less likely in the first place.
This work is operational. It needs process, tool discipline, and someone paying attention every day. For teams that do not want to own all of that internally, Reachly runs done-for-you multichannel outbound across email, LinkedIn, and phone, uses dedicated sending domains and verified data workflows, and manages sequencing, reply handling, and appointment setting so internal teams can focus on sales conversations instead of inbox maintenance.
If you want predictable outbound, treat deliverability like infrastructure. Because that is exactly what it is.
Book a working call if you want this built and run for you instead of managed piecemeal across inboxes, domains, data vendors, and sequencing tools.
FAQ
.webp)








